

iOS, Android Apps
Dictionary content from leading publishers
Access top-content dictionaries in one app.
Suitable for learning a language, preparing for exams, and more.
Suitable for learning a language, preparing for exams, and more.
Learn more about a language and break that language barrier!
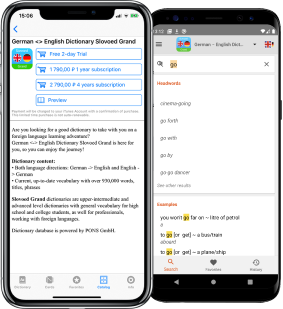
Conveniently use the app to learn the meanings of words, confirm proper word usage or syntax, and familiarize yourself with real life examples. The app is available for iOS and Android.
Conveniently use the app to learn the meanings of words, confirm proper word usage or syntax, and familiarize yourself with real life examples. The app is available for iOS and Android.







Dictionary content from leading publishers
An internal training program for memorizing new words
Advanced search opportunities, ability to create a list of your favorite entries
Flexible subscription options with a 2-day trial
Dictionaries

French — German
Dictionary
Dictionary

English — German
Dictionary
Dictionary

Spanish — German
Dictionary
Dictionary

AI-Mawrid AI-Hadeeth
Dictionary
Dictionary

Russian — English
Slovoed Deluxe Dictionary
Slovoed Deluxe Dictionary

German — Italian
Slovoed Deluxe Dictionary
Slovoed Deluxe Dictionary
Download Slovoed Dictionary Collection app


Contact Us
If you have questions related to Slovoed Dictionary Collection, you can contact our